
📝 Research summary: Exploring user preferences in AI image generation
A new paper suggests that users with clear creative goals prefer structured prompt creation via prompts, whereas those with less clear goals prefer open text inputs

An interesting preprint paper about image generation takes a stab at exploring user preferences for generating images with AI. The study (which, as a preprint, has yet to be peer reviewed) has an interesting finding: that the more explicit a user’s creative goals are with image generation, the more useful they tend to find structured prompt-modifying interfaces to create them. The less clear or explicit the user’s goals are, the more likely they are to favor open text fields to create an image.
Our results show that users from creative industries (e.g., designers, artists, and film directors) prefer choices-based input (i.e., Choices2I) due to its flexibility and control, regardless of their expertise level. These users often have clear creative goals and find the structured options helpful in achieving specific outcomes. Conversely, non-creative industry users, who typically use T2I models for entertainment or casual purposes, favor text-based input because it is simpler and imposes less cognitive load without the pressure of making choices.
There’s an interesting paradox when it comes to the empty text composer as a design element, particularly in the context of interacting with generative AI. On the one hand, it seems like the most accessible and understandable user interface imaginable. Want to create something? Just type what you want and it’s yours! On the other, what could be more intimidating than that? Where do you even begin? It’s both the lowest and the highest form of cognitive load to introduce to a user.
Consumer-facing AI image and video apps handle this cold start problem with varying degrees of heavy-handedness. Multimodal tools often offer lightweight starter suggestions for engaging with them, where they suggest a (likely new) user try to create an image by way of showcasing the model’s capabilities, as Meta does at meta.ai.
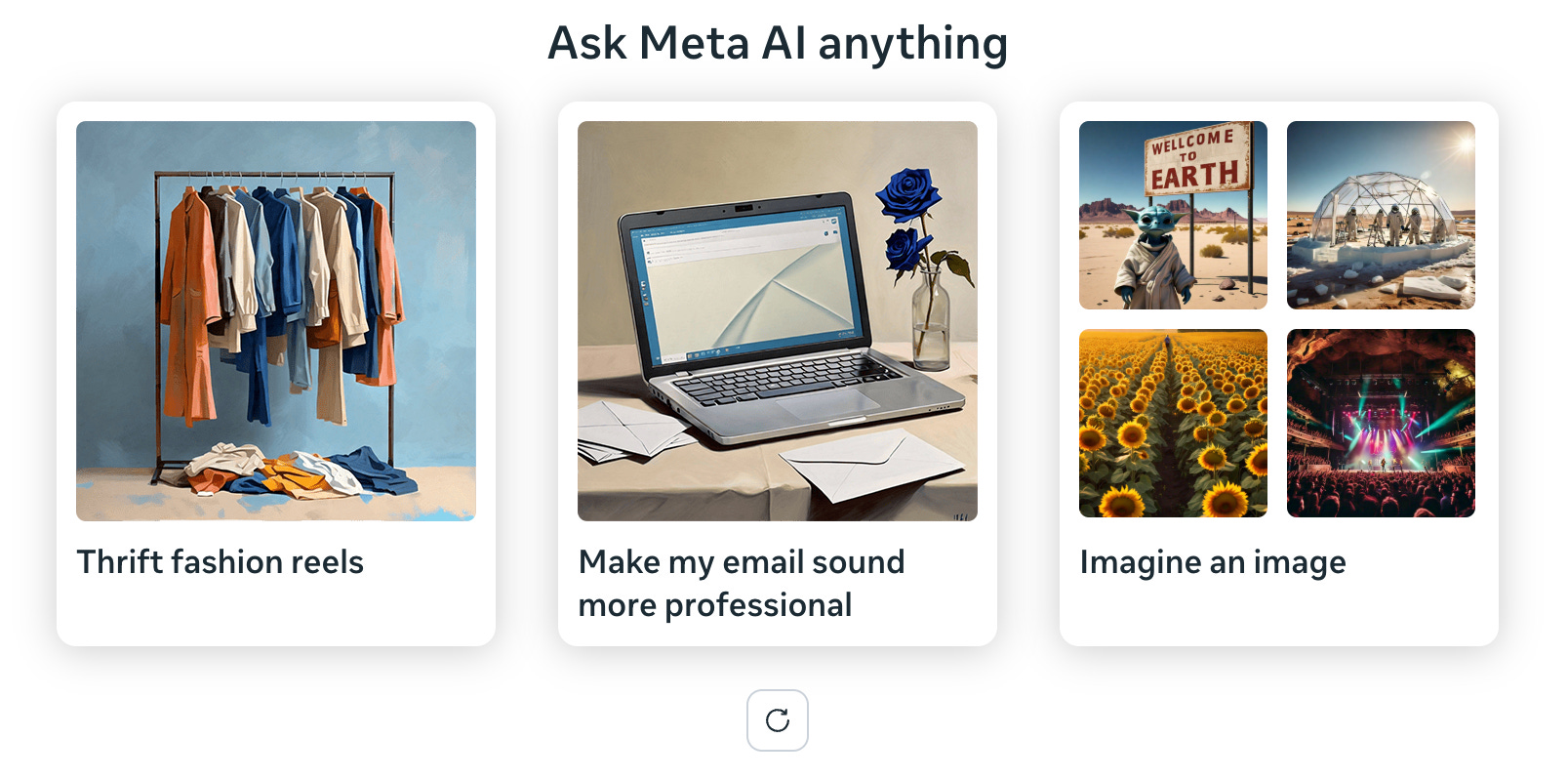
Further along the spectrum of nudging users towards specific types of prompting is something like what Luma does with their Dream Machine video model, where they have an empty composer, but with hovering prompt starters that encourage experimenting with its capabilities in terms of subject matter, lighting, and camera movement.

And at the opposite end of the spectrum from an empty composer, you have apps like Midjourney offering something similar in spirit (but more robust) to what the researchers did in the above paper. There’s an icon in the composer that reveals multiple ways to adjust the dimensions of your prompt via buttons and sliders.
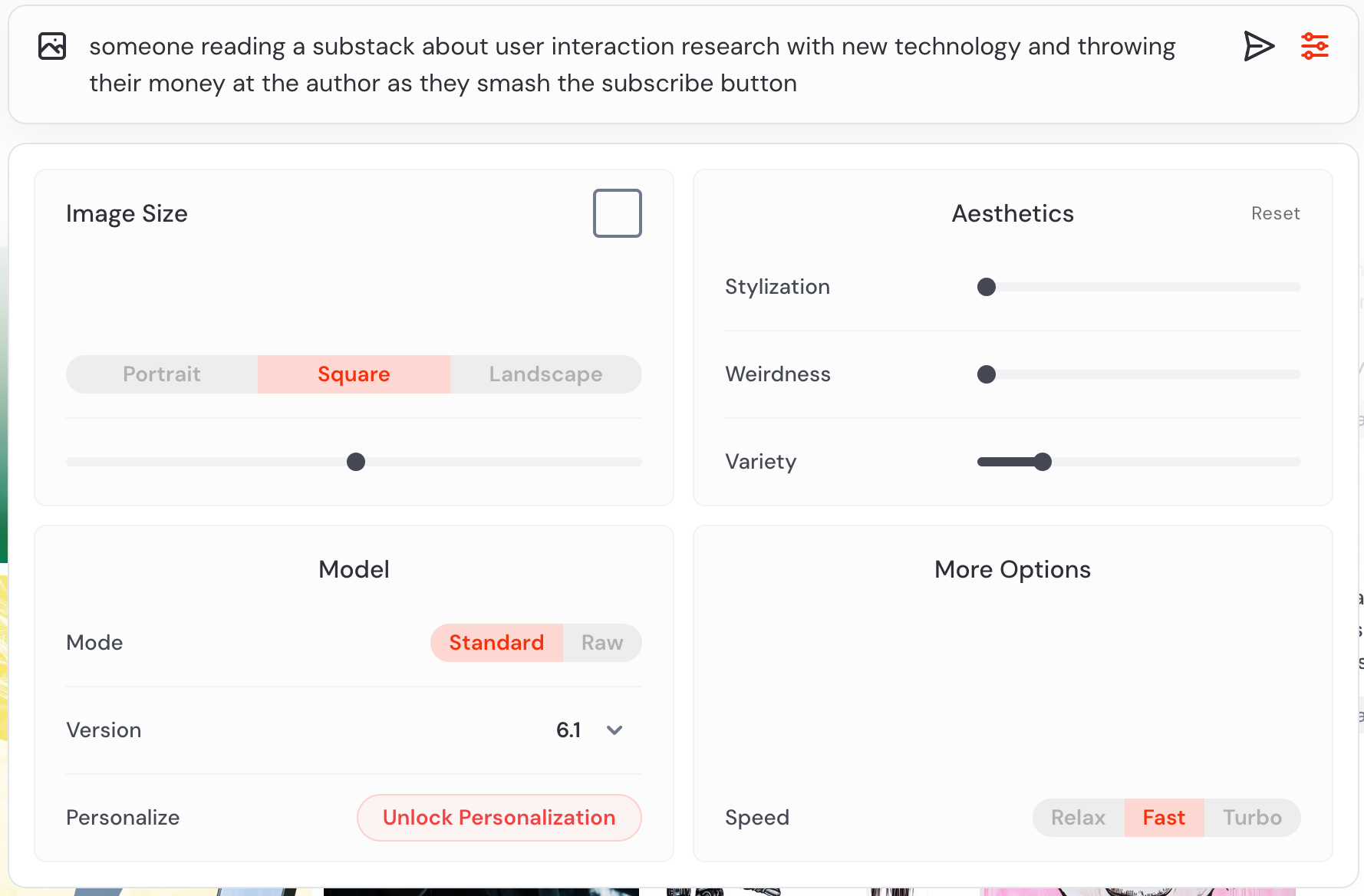
That Midjourney has moved in this direction on its web product is particularly telling, and seems to lend credence to the findings of the study. Midjourney is a tool that’s used heavily by a passionate community that loves experimenting with the model’s capabilities. That many of its users so actively share their prompts on Discord, X, and elsewhere is strong evidence that taming these models via text only is just, well… super hard.
So I imagine more professional creative AI tools will keep evolving in the direction of structured interfaces like this. But I think that raises some interesting questions that I hope future research will dig into and explore:
Do structured interfaces impede creativity by overly encouraging constraints? Will users of tools like this come to be overly reliant on dimensions like “Weirdness” as opposed to other dimensions they might explore via text-only or other types of interfaces?
How do people feel about and understand the relationship between structured interfaces that modify prompts and text-only prompts that accompany or are modified by using them?
Stay tuned.